
Attention is All you Need(Vaswani et al. 2017)
This is a Summary of the famous paper "Attention Is All You Need". This paper introduces the Transformer, a groundbreaking neural architecture based entirely on self-attention, revolutionising sequence-to-sequence tasks in natural language processing.
RESEARCH
Shubhradeep
1/1/20251 min read
Summary of "Attention Is All You Need" (Vaswani et al., 2017)
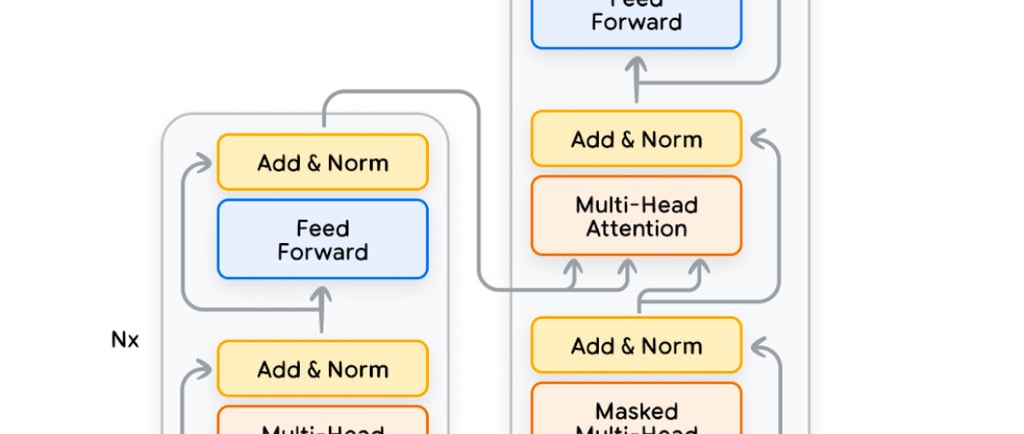
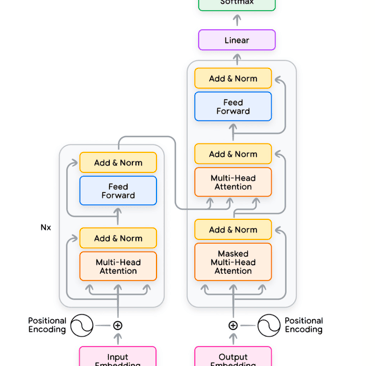
The paper "Attention Is All You Need" introduces the Transformer, a novel neural network architecture designed for sequence-to-sequence tasks such as machine translation. The Transformer replaces the need for recurrent and convolutional layers with a mechanism entirely based on attention. The key innovation is the use of the self-attention mechanism, which allows the model to focus on different parts of the input sequence dynamically, regardless of their distance in the sequence.
Key Features:
1. Architecture: The Transformer consists of an encoder-decoder structure. The encoder maps input sequences to continuous representations, while the decoder generates output sequences by attending to these representations and previously generated outputs.
2. Self-Attention Mechanism: Each position in the sequence attends to all positions, enabling the model to capture dependencies regardless of their relative position. This is achieved through scaled dot-product attention, calculated efficiently using matrix multiplications.
3. Positional Encoding: To preserve the order of the input sequence, positional encodings are added to the input embeddings, enabling the model to consider sequence order.
4. Multi-Head Attention: Instead of performing a single attention operation, the Transformer uses multiple attention heads, allowing it to capture diverse relationships in the data.
5. Feed-Forward Layers: Position-wise feed-forward layers add depth and non-linearity, improving the model's capacity to learn complex patterns.
6. Parallelisation: The Transformer architecture allows efficient parallelization during training, significantly improving computational efficiency compared to RNNs.
Results:
The Transformer achieved state-of-the-art performance on several translation benchmarks, including English-to-German and English-to-French tasks, and it became a foundational architecture for modern natural language processing models.
The paper’s insights have revolutionized NLP and inspired the development of models like BERT, GPT, and others, solidifying attention mechanisms as a cornerstone of deep learning.
AI430 - Agent HUB For Business Growth
Powering your Growth with our Successful Gen AI Solutions
Email Us
kalpita@ai430.com
© 2025. All rights reserved.